고정 헤더 영역

상세 컨텐츠
본문

728x90
https://www.acmicpc.net/problem/17140
17140번: 이차원 배열과 연산
첫째 줄에 r, c, k가 주어진다. (1 ≤ r, c, k ≤ 100) 둘째 줄부터 3개의 줄에 배열 A에 들어있는 수가 주어진다. 배열 A에 들어있는 수는 100보다 작거나 같은 자연수이다.
www.acmicpc.net

문제가 말하는 것이 어려워서
아래에 예시까지 봐야 이해가 잘 됩니다.
문제가 요구하는 걸 짚어보겠습니다.
0. A[r][c]==k를 만족하는지 보기.
(만족하면 time출력)
1. 행과 열 각각 뭐의 갯수가 더 큰 지 파악한다.
2. R연산 C연산 수행
(R연산-->행의 갯수가 더 큰 경우)
(C연산-->열의 갯수가 더 큰 경우)
3. 연산을 시켜준 후, 빈 공간에 0을 추가한다.
문제가 생각보다 복잡한 편입니다.
먼저, 가장 눈에 들어오는 거
행과 열 어떤 것의 갯수가 더 큰지를 파악해야겠죠?
이렇게 표를 그려보면
이해가 됩니다.
(편하신데로
아무 표를 그려보세요)
저는 임의대로
4X5를 그려봤습니다.
4X5는 행이 4개, 열이 5개입니다.
이 때는 가로가 더 긴 케이스죠??
즉, 가로가 더 길다-->열이 더 많다.
라는 것이 도출됩니다.
역으로
세로가 더 길다-->행이 더 많다
라는 것이 생각납니다.
여기까지는 그렇다치는데,
그렇다면 리스트의 가로세로를 어떻게 구할까요??
의외로 간단합니다.
graph=[list(map(int,input().split())) for _ in range(3)]
리스트를 이렇게 받을 때
가로-->len(graph[0])
세로-->len(graph)
위의 4*5 케이스로 다시 보겠습니다.
어처피 모든 행의 크기는 같습니다.
그러면 가장 맨 위에 있는
graph[0]의 길이가
가로의 길이가 됩니다.
(취향에 따라
graph[1],graph[2]
등으로 구하셔도 되지만
out of index의 위험도 있으니 유의!)
세로의 길이는
가로가 얼마나 있는가
즉, len(graph)로 구할 수 있습니다.
(만약 이해가 어렵다면, 직접 리스트를 선언하고
스스로 가로 세로를 구해보시면 감이 옵니다.)

다음은 연산을 해주는 작업입니다.
우선, 행이나 열에
0을 제외한 모든 숫자를 받습니다.
받은 후, 숫자를 정렬해줍니다.
그 뒤, 각각의 숫자가 얼마나 나왔는지 정리합니다.
저는 리스트에 덩어리로
[숫자,나온 횟수]
이렇게 정리했습니다.
그 뒤, '나온 횟수'를 기준으로 정렬했습니다.
이건 lambda정렬을 활용했습니다.
그 다음, temp라는 리스트에
각각의 행에
append 시켜줬습니다.
단, 이때 100을 넘어가면 안 되므로
100이상을 넣어주면 break
그 다음 0을 넣어주는 것.
temp행 중, 가장 긴 것을 기준으로
각 행에 0을 append해줬습니다.
각 행을 다시 돌아면서
(최대 길이-현재 길이)만큼 0을 append
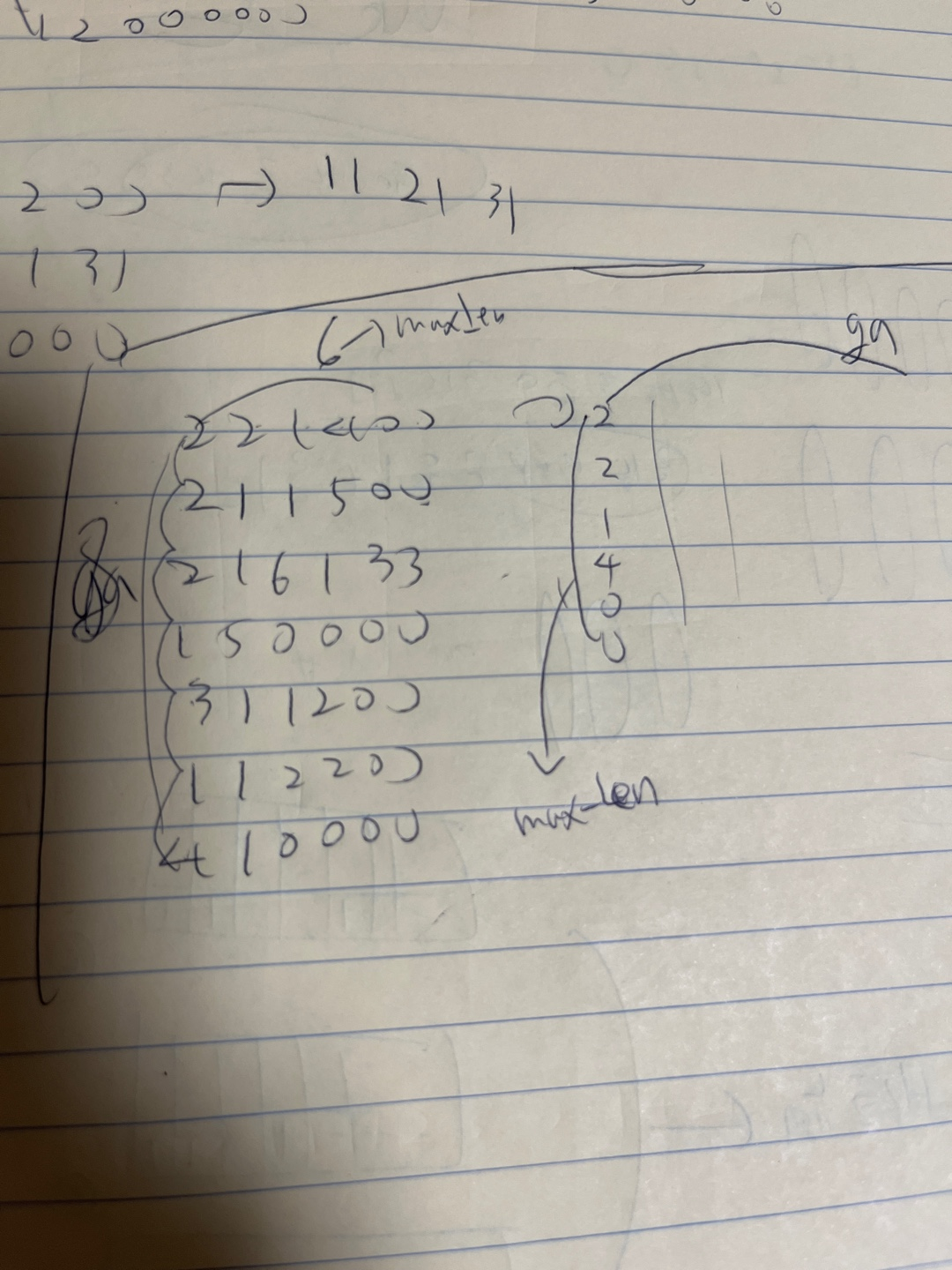
제가 가장 똥꼬쇼했던 부분.
C연산을 해주면
transpose를 시켜줘야합니다.
그래서 temp를 transpose시켰는데
클래식하게 새로운 리스트를 선언하되
가로 세로 크기를 바꿨습니다.
그 뒤, 알맞는 행렬에 넣어주는 식.
이런 식의 transpose를 할 때에는
가로 세로의 크기를 언제나 유의해주세요!!

이 문제에서 가장 곤란한 점은
마지막 테케입니다.
대부분의 사람들은
오!!나 다 풀었어!
하고 설레다가
마지막 테케에서 out of index가 발생하면서
당황스러워합니다.
그렇게 코드를 대폭수정하면서
맞왜틀을 반복...
out of index의 이유는 간단합니다.
'현재 리스트의 범위를 벗어났다'
연산을 하면서 그래프는 계속 변하기 때문에
때론 처음에 주어진 r,c값이
그래프를 벗어날 수 있습니다.
저 같은 경우에는
r,c값이 현재 가로,세로안에 있는지 확인해주는
별도의 처리를 통해 해결했습니다.
# 백준 17140 이차원 배열과 연산
from copy import deepcopy
r, c, k = map(int, input().split())
r -= 1
c -= 1
graph = [list(map(int, input().split())) for _ in range(3)]
"""
temp=[[False]*2 for _ in range(4)]
print(len(temp))
print(len(temp[0]))
"""
time = 0
while time <= 100:
ga = len(graph[0])
sa = len(graph)
# 범위체크를 해주는 이유--> 행렬의 크기가 바뀔 수 있기 때문.
if 0 <= r < sa and 0 <= c < ga:
if graph[r][c] == k:
break
# print(ga,sa)
# R연산(행의 개수>= 열의 개수-->세로가 더 큰 경우)
if sa >= ga:
temp = [[] for _ in range(sa)]
max_len = 0
for x in range(sa):
data = []
tmp = []
# 0빼고 가로에 있는 걸 전부 넣음
for y in range(ga):
if graph[x][y]:
tmp.append(graph[x][y])
tmp.sort()
now = tmp[0]
group = 1
if len(tmp) == 1:
data.append([now, group])
for y in range(1, len(tmp)):
if tmp[y] == now:
group += 1
else:
data.append([now, group])
now = tmp[y]
group = 1
if y == len(tmp) - 1:
data.append([now, group])
# group의 수대로 정
data = sorted(data, key=lambda x: x[1])
for da in data:
temp[x].append(da[0])
temp[x].append(da[1])
if len(temp[x]) >= 100:
break
now_len = len(temp[x])
max_len = max(max_len, now_len)
# max_len=max(max_len,sa)
for x in range(sa):
for _ in range(max_len - len(temp[x])):
temp[x].append(0)
graph = deepcopy(temp)
# C연산
else:
temp = [[] for _ in range(ga)]
max_len = 0
for y in range(ga): .
tmp = []
# 0빼고 세로에 있는 데이터를 모두 구함
for x in range(0, sa):
if graph[x][y]:
tmp.append(graph[x][y])
tmp.sort()
data = []
now = tmp[0]
group = 1
if len(tmp) == 1:
data.append([now, group])
for x in range(1, len(tmp)):
if tmp[x] == now:
group += 1
else:
data.append([now, group])
now = tmp[x]
group = 1
if x == len(tmp) - 1:
data.append([now, group])
data = sorted(data, key=lambda x: x[1])
for da in data:
temp[y].append(da[0])
temp[y].append(da[1])
if len(temp[y]) >= 100:
break
now_len = len(temp[y])
max_len = max(max_len, now_len)
# max_len=max(max_len,ga)
for y in range(ga):
for _ in range(max_len - len(temp[y])):
temp[y].append(0)
temp2 = [[0] * ga for _ in range(max_len)]
# print(temp)
# print(max_len)
for x in range(max_len):
for y in range(ga):
# print(x,y)
temp2[x][y] = temp[y][x]
graph = deepcopy(temp2)
time += 1
# print(graph)
# print()
if time > 100:
print(-1)
else:
print(time)
https://pacific-ocean.tistory.com/380
[백준] 17140번(python 파이썬)
문제 링크: https://www.acmicpc.net/problem/17140 17140번: 이차원 배열과 연산 첫째 줄에 r, c, k가 주어진다. (1 ≤ r, c, k ≤ 100) 둘째 줄부터 3개의 줄에 배열 A에 들어있는 수가 주어진다. 배열 A에 들어..
pacific-ocean.tistory.com
https://deok2kim.tistory.com/251
[python] 백준 - 17140. 이차원 배열과 연산
🤔문제 해결 G4 | 시뮬레이션, 구현 문제를 이해하는데 시간이 좀 걸렸다. k값이 맞는지 확인하고 아니라면 시간을 +1 증가시킨다. R연산인지 C연산인지 확인한다. R 연산일 경우 각 행의 숫자와
deok2kim.tistory.com
썡 구현외에
간단하게 내장함수를 사용하는 방식도 있습니다.
공부의 측면에서, 여러 방식을 익혀두는 것도 좋아보입니다.
(다만, 실제 문제가 나온다면
어쩔 수 없이 썡구현하는 케이스가 많으므로
저는 쌩구현이 더 좋아보이네요)
728x90
'알고리즘 공부' 카테고리의 다른 글
| [백준 14899번] 스타트와 링크(파이썬) (0) | 2022.04.24 |
|---|---|
| [백준 19236번] 청소년 상어(파이썬) (0) | 2022.04.23 |
| [백준 14502번] 연구소(파이썬) (0) | 2022.04.21 |
| [백준 21611번]마법사 상어와 블리자드(파이썬) (0) | 2022.04.20 |
| [백준 20061번] 모노미노도미노2(파이썬) (0) | 2022.04.20 |





댓글 영역
Tabris4547님의
글이 좋았다면 응원을 보내주세요!
이 글이 도움이 됐다면, 응원 댓글을 써보세요. 블로거에게 지급되는 응원금은 새로운 창작의 큰 힘이 됩니다.
응원 댓글은 만 14세 이상 카카오계정 이용자라면 누구나 편하게 작성, 결제할 수 있습니다.
글 본문, 댓글 목록 등을 통해 응원한 팬과 응원 댓글, 응원금을 강조해 보여줍니다.
응원금은 앱에서는 인앱결제, 웹에서는 카카오페이 및 신용카드로 결제할 수 있습니다.