고정 헤더 영역

상세 컨텐츠
본문
728x90
레지스터

이야기에 앞서, 레지스터라는 것에 대해 알아보겠습니다.
레지스터(register)는 중앙 처리 장치(CPU)의 일부분으로
데이터를 '임시보관'하는 메모장과 같습니다.
컴퓨터가 동작할 때, 수많은 연산들이 오고갑니다.
변수를 선언하고 그 변수에 값을 집어넣는 등등
여러가지 일을 수행합니다.
그럴 때 레지스터에 값을 임시로 저장하면서
메모리로 매번 데이터를 부르는 수고를 덜어줍니다.
C코드를 어셈블리어로
그럼 실제 코드는 어떻게 동작할까요?
C코드를 어쌤블리코드로 바꾸는 과정을 보면서 이해하겠습니다.
f=(g+h)-(i+j);다음의 C코드는 어쎔블리로 다음과 같이 바뀝니다.
(x20->g
x21->h
x22->i
x23->j
이렇게 각각의 변수에 대한 임의의 값이
해당 레지스터에 저장되어있다고 가정합니다.)
add x5, x20, x21// register x5 contains g + h
add x6, x22, x23// register x6 contains i + j
sub x19, x5, x6// f gets x5 –x6, which is (g + h)−(i + j)먼저 (g+h)연산을 수행합니다.
+연산이므로 add연산을 통해
x20과 x21의 값을 더한 것을 x5라는 레지스터에 저장합니다.
그 후에는 (i+j)연산을 수행합니다.
같은 방식으로 연산결과를 x6레지스터에 저장합니다.
마지막으로 x19레지스터에 x5 x6레지스터에 저장된 값을 빼준 값을 저장합니다.
Load & Store
(data transfer Instruction)
그런데, 여기서 끝나면 메모리에는 저장되지 않습니다.
레지스터는 임시저장만 하기 때문에
이 값들을 메모리에 저장해야합니다.
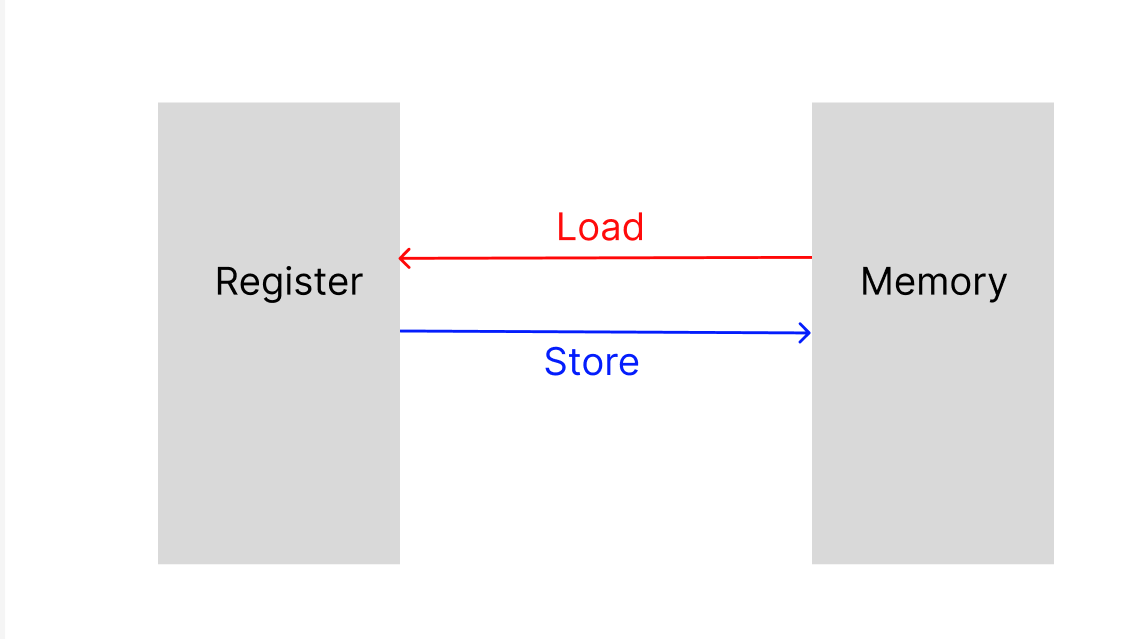
그래서 레지스터와 메모리에
서로 데이터를 불러오고 쓰는 명령이 있습니다.
메모리의 데이터를 레지스터에 쓰는 명령이 Load
레지스터의 값을 메모리에 저장하는 명령이 Store
메모리의 값을 불러오거나 저장할 때,
메모리의 주소값을 참조합니다.
A[12] = h + A[8];이 코드를 Load,Store의 과정을 거치면 어떻게 될까요?
ld x9, 64(x22) // Temporary reg x9 gets A[8]
add x9, x21, x9 // Temporary reg x9 gets h + A[8]
sdx9, 96(x22)// Stores h + A[8] back into A[12]우선 ld명령어로 메모리에 저장된 A[8]의 값을 불러옵니다.
그러면 x9레지스터에 A[8]값이 임시저장이 됩니다.
연산을 마친 후, x9에 저장된 값을
메모리의 A[12]주소에 store시킵니다.

그림으로 한번 더 살펴보겠습니다.
먼저, load명령어부분입니다.
A[8]의 값이 있는 Momory의 64번지 값을
레지스터 x9에 load시킵니다.

그 후, x9레지스터에 저장된 값을
A[12]의 값이 저장된
메모리 96번지에 store를 시킵니다.
(참고:원래 Risc-V 레지스터는 32비트지만
편의상 16비트처럼 묘사했습니다)
Instruction Format


우리는 컴퓨터가 0,1 두가지만으로 연산하는 걸 알고있습니다.
그런데 어쌤블리 코드는 숫자가 아닌데 이를 어떻게 해석할까요?
그래서 컴퓨터가 이해할 수 있게
machine language로 변형한 machine코드를 활용한 명령어구조를 활용합니다.
그림의 명령어는 ARM코어기준으로
연산(DP)과 데이터전달(DT)의 구조가 각각 어떻게 되는지 설명하고 있습니다.

오늘날 컴퓨터는 2가지 규칙으로 만들어집니다.
1.명령들은 숫자로 표현된다.
2.프로그램은 데이터처럼 메모리에 저장되고
읽기,수정된다.
이런 규칙에 의거한 개념이 바로
"Stored-program concept"입니다.
그래서 instruction에 기록된 데이터대로
명령들이 차례대로 수행됩니다.

반복문에 대한 동작
위에 제시한 원리를 반복문 동작 케이스를 보면서 이해해보겠습니다.
while (save[i] == k)
i += 1;이런 간단한 반복문 코드가 있습니다.
Loop: slli x10, x22, 2 // Temp reg x10 = i * 4
add x10, x10, x25 // x10 = address of save[i]
ld x9, 0(x10) // Temp reg x9 = save[i]
bne x9, x24, Exit // go to Exit if save[i] ≠ k
addi x22, x22, 1 // i = i + 1
beq x0, x0, Loop // go to Loop
Exit:(해당코드는 Risc-V로 작성한 코드입니다)
x22->i
x24->k
x25->save
이렇게 각각 저장되어있다는 가정입니다.
slli라는 명령어를 통해 x22의 값(i)을 3만큼 shift시킨 값을
x10의 레지스터에 저장합니다.
앞으로 나올 그림에서는 32bit체제에서의 그림을 가정했기 때문에
array의 주소값이 4씩 차이가 납니다.
2023.09.24 - [CS지식 학습] - (어그로 아님) int자료형은 언제나 4바이트가 아니다
(어그로 아님) int자료형은 언제나 4바이트가 아니다
이 제목을 보자마자 여러분들은 어떤 생각이 드셨나요? "??int가 4바이트가 아니라고요?? 코딩배울 때 int 4바이트라고 배웠고 그거 기본중에 기본아님??" 이런 생각 드신 분 계신가요?? 저도 이 말
door-of-tabris.tistory.com
(이에 대한 설명은 이 글을 참고해주세요)
그 x10레지스터에 save[i]의 주소값을 추가합니다.
그 후, x9에 x10에 저장된 주소값을 참고하여 save[i]의 값을 load합니다.
그후 bne를 통해 x9와 x24를 서로 비교합니다.
만약 두 값이 같다면 다음동작을 수행하고
그렇지 않다면 Exit으로 넘어갑니다.
x9 x24값이 같다면, x22의 값에 1를 추가합니다.
그 후, 루프로 다시 돌아갑니다.
(참고:레지스터를 32개까지 그려야하지만
편의상 다음과 같이 그렸습니다.
레지스터 어디에 저장되고 계산하는지 위주로 봐주세요)

먼저 x25에 save의 주소값을 로드했다는 가정.

현재 i=0이므로
2shift시킨 값은 0입니다.

x25에 저장된 save배열의 주소값을
x10의 현재값과 더합니다.
a+0=a
x10에는 주소값 a가 저장이 됩니다.

x10에 저장된 주소값을 통해
x9에 값을 load시킵니다.
현재는 i가 0입니다.

현재는 x9의 값이 x24의 값과 같기 때문에
반복문을 수행합니다.
그 후, x22의 값에 1을 추가합니다.

이제 다시 루프문을 수행합니다.
i=1이고 이걸 2shift시키면 4가 됩니다.
x10에서는 4가 저장됩니다.

x25에 저장된 save 배열의 주소값을 add시키면
이제 x10에는 a+4가 저장이 되고
이후에는 save[1]의 값을 x9이 load할 수 있게 됩니다.
이런 식으로 array의 값들을 확인하다가
i=5일 때 save[i]의 값이 6이 되어
k와 다르기 때문에 반복문이 종료가 됩니다.

반복문 안의 수행문중
루프를 돌면 무조건 수행되는 block을 basic block이라고 부릅니다.
위의 반복문을 수행하면
i+=1;이라는 명령은 무조건 수행되니
이 부분이 basic block에 해당됩니다.
컴파일러는 최적화를 위해
이 basic block에 해당하는 범위를 찾고
결과만 같으면 되기 때문에
필요없는 부분의 코드를 생략하기도 합니다.
레지스터와 코드 최적화의 관계
레지스터는 메모리보다 속도가 빠른 대신에
사용량이 제한되어있습니다.
32비트 레지스터라면 최대 32개의 레지스터가 사용가능합니다.
이런 부분이 있어 코드를 작성할 때 최적화에 신경쓸 부분이 있는데요.
불필요한 변수사용 줄이기
int a=3;
int b=4;
printf("숫자 출력:%d\n",a);// b는 쓰이지 않음간단하게 숫자를 출력하는 코드입니다.
a b을 선언했기에, 레지스터 각각에 값을 넣어줍니다.
하지만 b는 한번도 쓰이지 않았기 때문에
b의 값을 할당한 레지스터는 낭비가 됩니다.
코드가 복잡해지고 변수가 많으면
불필요한데 선언해버린 변수로 인해
코드 실행시간이 줄어들기 때문에
사용하지 않는 변수는 줄이는 것이 좋습니다.
직접연산
int a=3;
int b=4;
int c=a+b;직접연산은 레지스터끼리 계산하는 연산입니다.
c에 값을 할당할 때에는 a b 레지스터값을 add한 결과를 넣기 때문에
memory에서 load후 값을 넣는것보다 훨씬 빠른 연산이 가능합니다.
반복적으로 쓰이는 변수
register int k=0;
while(k<10){
printf("hello world\n");
}C에서는 변수선언 앞에 register를 붙이면
register에 값을 할당할 것을 명시합니다.
다음과같이 반복문에 쓰이는 변수를 register에 넣을 경우
register에서 빠르게 값을 불러오기 때문에
프로그램 실행속도가 더 빠르게 증가할 수 있습니다.
파이프라인 속도와 레지스터의 관계

파이프라인 속도관점에서
레지스터를 다시 바라보겠습니다.
프로그램이 명령을 수행할 때
파이프라인으로 동작합니다.
그림을 보면, 동작을 수행할 때
앞선 변수의 값에 의존하는 경우가 생깁니다.
이를 '데이터의존성'이라고 부르며
그림을 보면 sub x2,x1 x3 연산한 후
그 결과를 register에 write하고 있으며
이 값이 어디에 의존되는지 나타내고 있습니다.
문제는 두번째,세번째,네번째 동작을 수행할 때
register에서 값을 로드해야할 때 입니다.
첫번쨰 명령에서 write를 할 때는 CC5클락이기 때문에
다섯번째 명령처럼 CC5클락 이후에 register값을 load할 때는
x2의 값이 반영되지만
나머지명령어는 그 이전과 그 때의 클락이기 때문에
해당 값이 반영되지 않습니다.

이럴 경우에는 파이프라인 구조를 개선하여
이런 데이터의존성을 최소화할 수 있지만
구조개선만으로 힘든 경우가 생깁니다.
그래서 위의 그림처럼 nop명령어(bubble)를 넣어
and x4,x2,x5명령어가 한 클락 뒤에 실행되도록하여
데이터의존성을 해결하는 경우가 있습니다.
이렇게되면 전체적인 프로그램 시간이 증가하는 문제가 생깁니다.
그래서 컴파일러는 이런 문제를 최소화하기 위해
데이터의존성을 최소하하는 방향으로
명령어순서를 조정합니다.
참고자료
Computer Organization and Design RISC-V edition
숭실대학교 박민호 교수님 컴퓨터구조 강의자료
728x90
'CS지식 학습' 카테고리의 다른 글
| 메모리와 명령어의 상호작용, 왜 알아야할까?? (1) | 2023.10.10 |
|---|---|
| 2진수계산,왜 알아야하고 어떻게 사용할까?? (1) | 2023.10.08 |
| (어그로 아님) int자료형은 언제나 4바이트가 아니다 (0) | 2023.09.24 |
| Call by value vs Call by reference??? (C언어 고찰) (0) | 2023.09.23 |
| for와 while문, 왜 반복문은 2개가 있을까??(C언어 고찰) (2) | 2023.09.23 |





댓글 영역